

I remember trying out the LM Studio a few months back, then due to the slow performance of my system, I decided to uninstall it and wait for the updates.
Then yesterday I saw the Llama 3.1 update and Mark’s blog about open-sourcing AI models. So I thought let’s explore again LLMs locally.
I tried Text Generation web UI first and tried to load the openchat-3.5-0106-GPTQ from TheBloke. And still, the generation is slow. But I know it is because of my hardware1.
Anyway, so as a second attempt, I installed LM Studio again to explore LLMs locally. That’s when I saw the compatibility status along with each model. It will tell whether the model will fully support my system, partially support it, or likely not support it. Now, that gives me something to work with.
Also decided to install Ollama - an open-source platform to run LLM locally.
So I searched for models that were most popular and matched my criteria. There are many available. So I spent some time in Perplexity to learn what I should look for with my specifications.
According to Perplexity, my best options are Quantized Models2. So I downloaded five models from Hugging Face and Ollama library to try out.
Meta-Llama-3.1-8B from
meta-llamagemma-2b-it-GGUF from
lmstudio-aiPhi-3 Mini -3.82B from
microsoftstablelm-2-1_6b from
stabilityaiqwen2-0.5b from
qwen
So in simple terms, you need to understand your device specifications and look for modal cards that suit.
Both Hugging Face and Ollama display model cards.

How to run LLMs locally using LM Studio?
It’s a straightforward process. Because it’s all UI-based. Anyone can figure it out if they spend a few minutes to understand the interface. You can see the size and compatibility status when you search for a model.
Install https://lmstudio.ai

Download the models you need and they will be downloaded to the default path
C:\Users\ComputerName\.cache\lm-studio\models
Now go to the AI Chat tab and load a model, adjust the settings (this is a bit tricky, you need to find the optimal performance settings by tweaking multiple times).
When in doubt, there will be an information icon with every string, just hover it and read.
I gave max GPU usage to Gemma 2 from lmstudio-ai and it generated content at lightning speed. I played around a little and I think I can find an appropriate use case for it soon. Also note that when running locally, the context size will be very low due to the low-end hardware system.
How to run LLMs locally using Ollama?
My first impression was a little bit tough. I didn't quite understand how to use this. because it’s just a Terminal. So I had to spend some time to understand what everything is. So I’ll try to explain in the best simplest way possible (I’m a Windows user, so the terms will be based on Windows).
Install Ollama from the website https://ollama.com
After installation open a Terminal (Command Prompt or Windows PowerShell)
It will display the general user root
C:\Users\ComputerNameType
Ollamaand hit enter. It will display a set of lists (Just to familiarize)

Go to the Ollama Model Library and find the appropriate and suitable model by understanding your device’s capability.
After finding one, just click on it and it will open the model screen.

Now all you have to do is make sure the latest is selected and click on that copy icon along with the command to pull this model to your system, in this case,
ollama run phi3:latestBack to the Terminal, paste the command, and hit enter. It will start to download the model to your system (Check your Terminal for updates). You can find the path here
C:\Users\ComputerName\.ollama\models\blobsAfter a successful download, you will see a subtle colored command.
>>> Send a message(/? for help)This means you’re now running that LLM locally, you can ask anything and it will answer momentarily (If your system can hold the weight of the LLM).
Even though it looks a little bit of a developer style, it is easy.
To run it again;
You can close this Terminal anytime and whenever you need to run it again just open a Terminal and run that command from the Ollama model library or just type your LLM name (Ollama run phi3:latest)
If it feels a little complicated to navigate, there is another way. You can use it like ChatGPT/Gemini style.
How to run LLMs locally using Open WebUI?
Install Ollama
Install Docker
After successful installation of both, go to the Open WebUI’s Github repository.
Scroll down to documentation and find the command for your requirements. I choose to run “To run Open WebUI with Nvidia GPU support”.
Copy and paste that command to the Terminal and wait for the installation to finish.
After successful installation, open the
Docker Desktopfrom the apps.Select the container tab and there will be one container configured.
The container is already running by now, so look at the table. There will be a column named “Port”, click on the hyperlink. It will open
http://localhost:3000Click on sign up and create a single account (Everything is running locally, not online). This account is just for a user account purpose.
Now you can see the Open Web UI - familiar right?
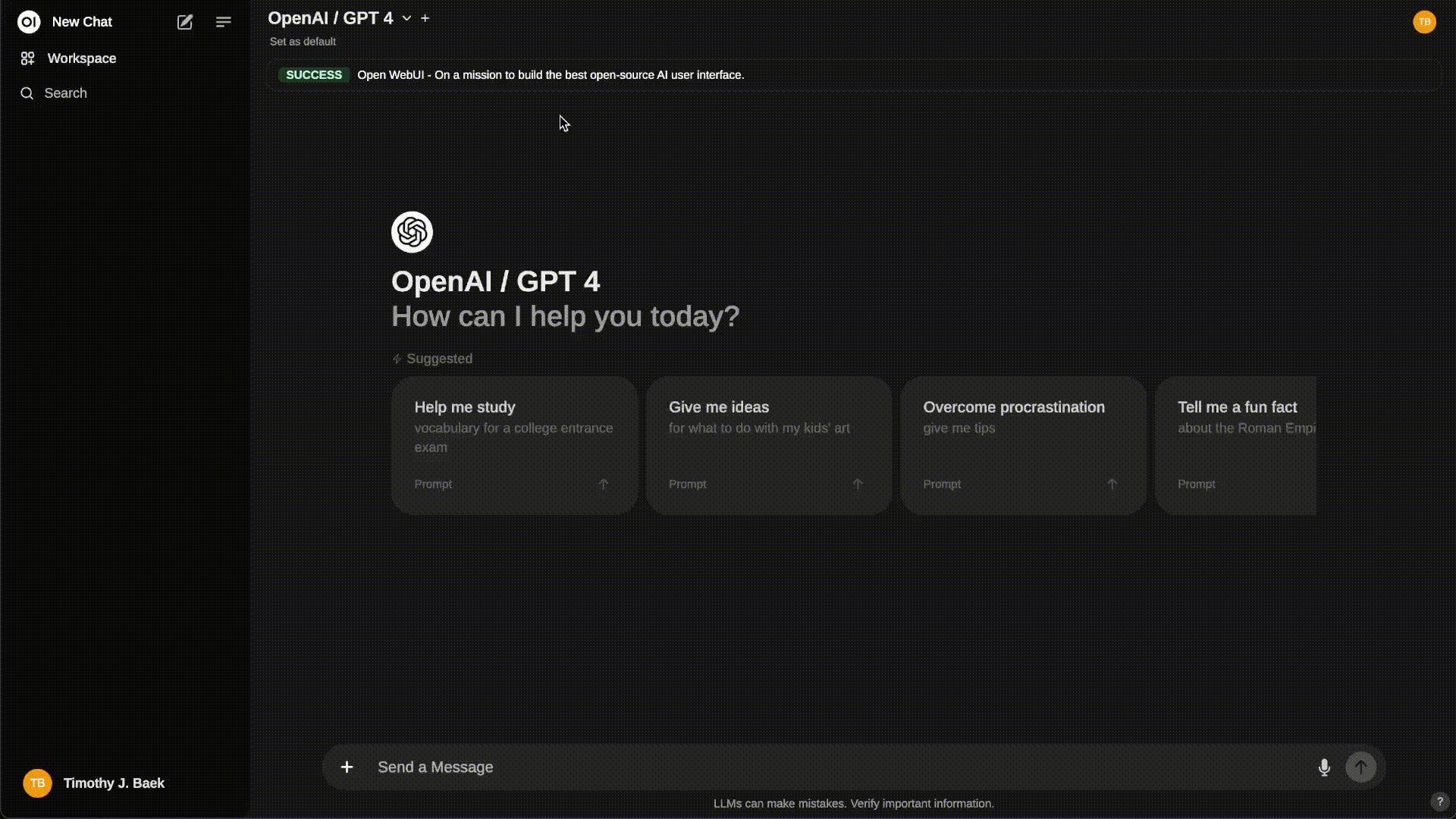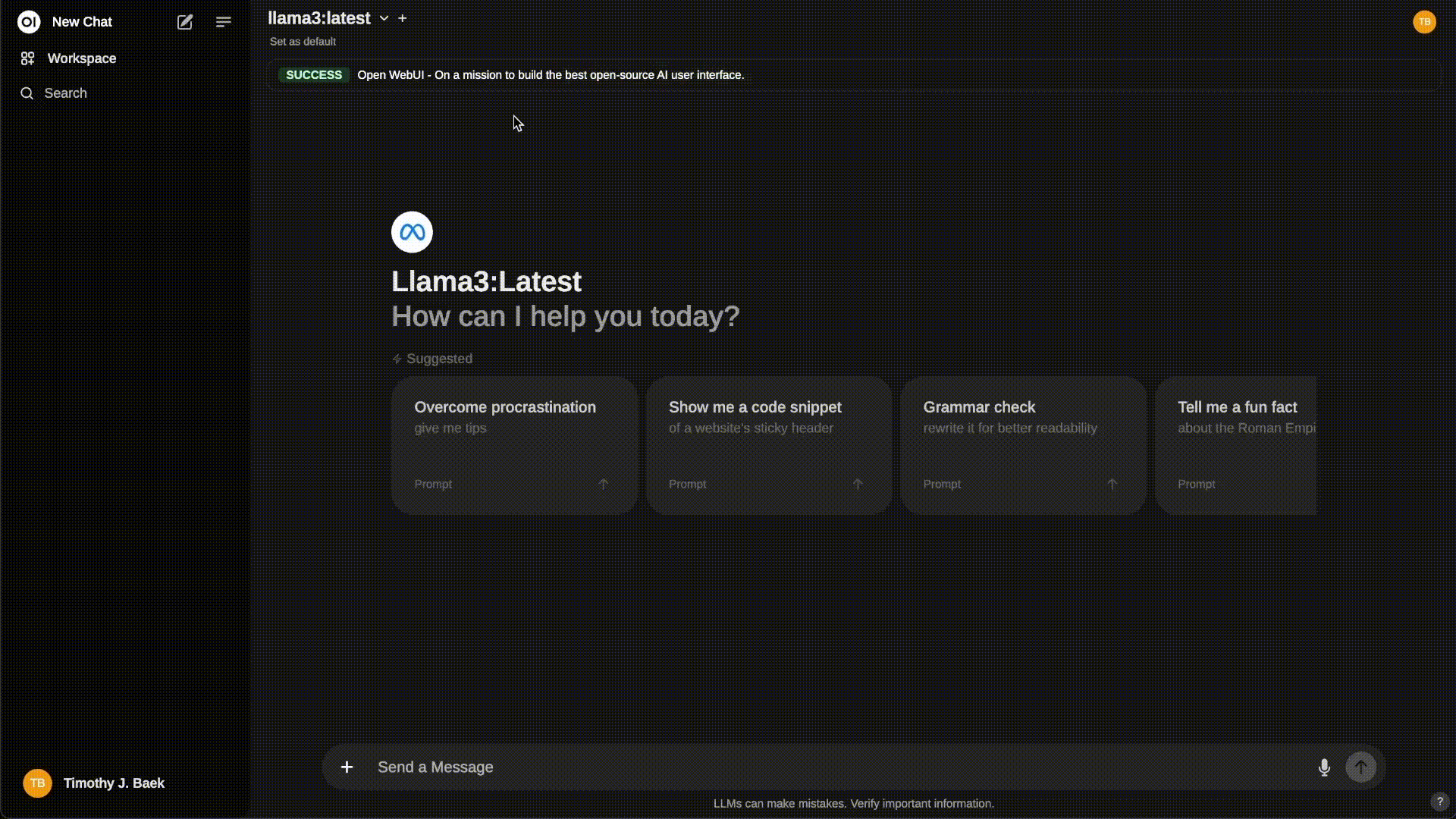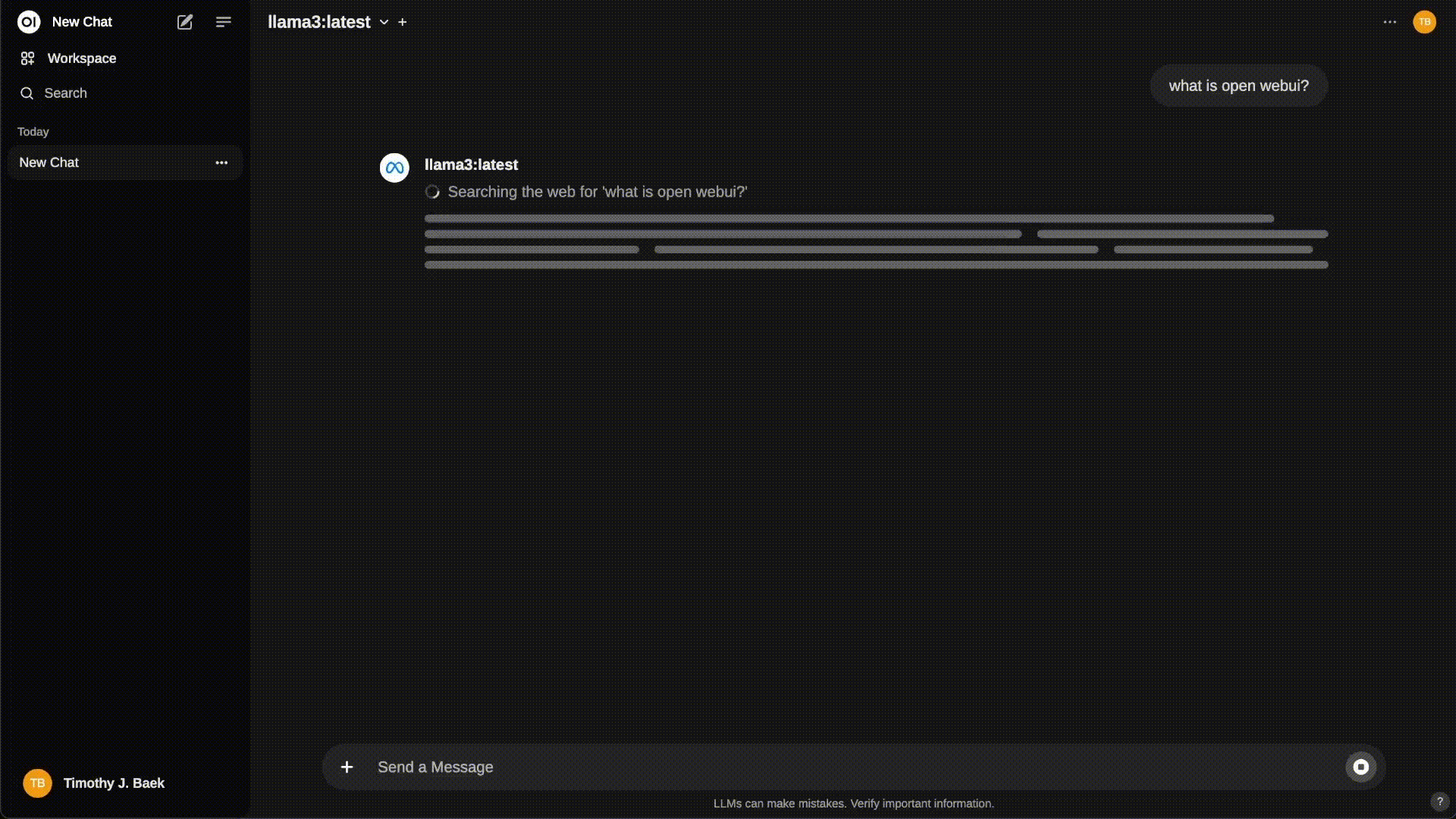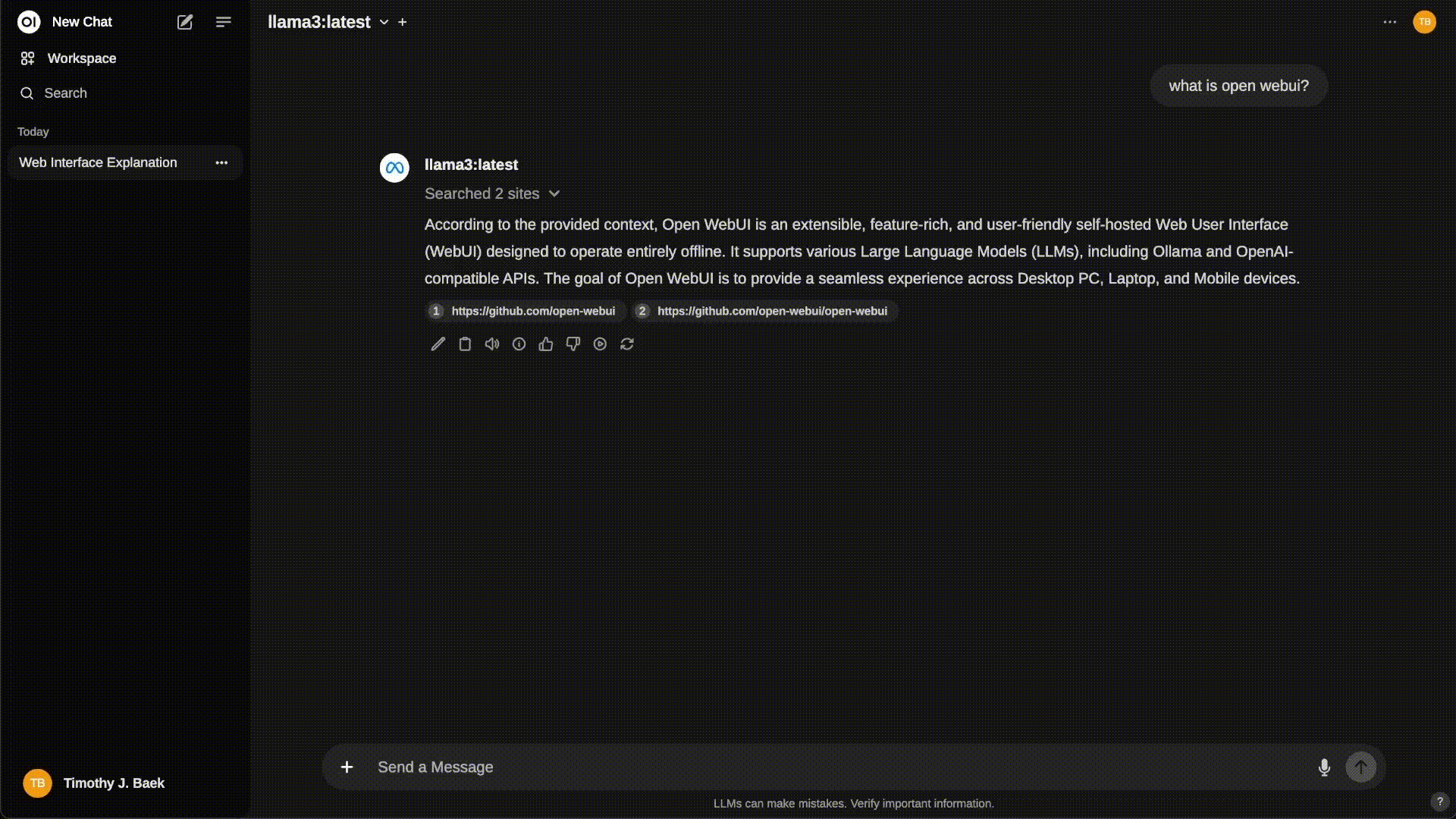
Just select a model and ask away.
Do not forget to tweak the settings to your needs.
You can load multiple models and ask questions (but it depends on your system).
The UI has a lot of useful features. Play around and find everything.
Now when you finished, you can close the tab and quit the docker from the taskbar.
When you need to open it again, just open the
Docker Desktopand clickhttp://localhost:3000
How to load a gguf model downloaded from Hugging Face in Ollama
Now you may have gguf models downloaded with LM Studio, or direct from Hugging Face, right? You can load this in Ollama.
Save the gguf file in a dedicated folder. I have a gguf file
gemma-2b-it-q8_0.ggufand I saved it in the pathE:\AI\lmstudio-ai\gemma-2b-it-GGUFNow create a note file in the same directory and type the following.
FROM E:\AI\lmstudio-ai\gemma-2b-it-GGUF\gemma-2b-it-q8_0.ggufSave the file as a text (file name must be
Modelfile)and remove the extension (Press F2 and remove the.txt).Now you have two files in that directory, right? One is a gguf file and the other is a file without any extension and named Modelfile.
While you’re in the folder where these files are stored, right-click and select
Open in Terminal.This will open a Terminal that is now ready to do things in this directory, nothing complicated.Now the final part, type
ollama create gemma-2b-it -f ModelfileJust remember that
gemma-2b-itin the above command is a name I gave, you can change it to your model name. It will create a model and you can run it like usual. Type and enterOllama listto see the available models. It will be available in the Open WebUI too. Just play around.

I’m waiting for smaller models or ones that can be configured to our specific needs online and downloaded in smaller sizes. I believe future devices will focus on this, making the process easier.
Please note: Running LLMs locally is a process of huge power consumption and the laptop will produce more heat than usual. So, for very simple things, use any cloud-based AI services. My current recommendations are Claude and Perplexity.
I’m happy that all this is possible now and all we need is more optimization to run it smoothly and efficiently. There will be many use cases like talking to a computer in real-time and getting appropriate answers even when the internet is not available, handling with a company, or personally sensitive data, etc.
Related

{kind=link}
8GB RAM, AMD Ryzen 7 5800H CPU, which has 8 cores and 16 threads, and an NVIDIA GeForce GTX 3050 GPU 4GB.
These models reduce the precision of the weights, allowing them to consume less memory.